Voice Cloning: Behind Your Digital Vocal Twin
- Aastha Thakker
- Oct 29, 2025
- 6 min read


Hey there!
Today, we will see one of the most interesting use cases of AI: voice cloning. When I asked people what they understood by voice cloning, I received multiple different answers — some were correct, but many were not.
Before we begin exploring what voice cloning is, let’s understand why it’s necessary. And being poetically dramatic, I’m sharing a poem which relates to “the voice.”
Voice is a blade wrapped in a gentle tone, It builds or breaks what hearts may keep, A whisper can shake even the stone. It guides the lost or leads to deep, When used with thought, it stands alone — But wild and loud, it drowns in cheap.
So yeah, now getting back to technicalities!
What is voice cloning?
Voice cloning is essentially creating a digital copy of someone’s unique vocal identity. It is basically capturing the essence of how someone speaks, their unique tone, rhythm, and distinctive quirks, and then using technology to make that voice say brand new things they’ve never actually said.
From a technical perspective, this works through a sophisticated pipeline of artificial intelligence and signal processing. The process begins with collecting voice samples from the target speaker. These recordings are fed into deep neural networks that analyze countless dimensions of the voice: the specific frequencies that give it warmth or brightness, the micro-pauses between words, the way certain vowels are stretched or compressed, and the characteristic rise and fall of pitch that makes each voice instantly recognizable.
These neural networks essentially build a mathematical model of the voice, learning to predict what a particular sound or word would sound like if spoken by that specific person. Modern architectures like WaveNet and transformer-based models can map the relationship between text and sound with remarkable accuracy.
Voice cloning isn’t just a fancy cousin of text-to-speech (TTS) or speech-to-text (STT), even though they all hang out at the same AI family reunion.
TTS? That’s your basic speech synthesizer. It takes plain text and spits out robotic or slightly improved speech, depending on the model.
STT? It’s doing the opposite — turning spoken words into written ones, like a digital stenographer.
But voice cloning? That’s a different beast altogether.
This one doesn’t just want to “speak” — it wants to speak like you.
And thanks to advancements in neural networks and deep learning, these replicas have gotten so lifelike, they don’t just say things you said — they say things you never did, but people might believe you did.
Creepy? A bit.Cool? Totally.Powerful? Absolutely.
And that’s why it’s critical to understand this technology, not just how it works, but what it could mean.
Use Cases of Voice Cloning:
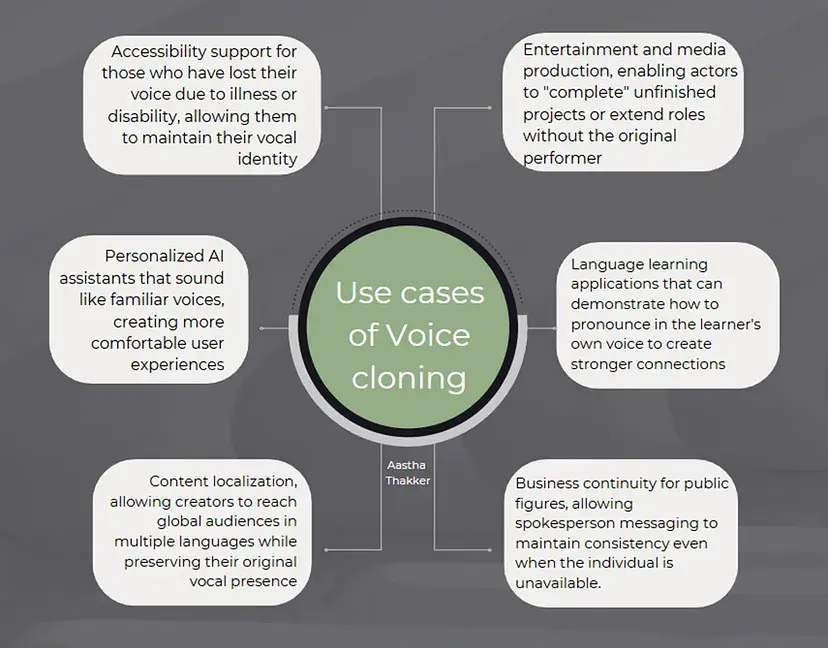
Why Voice Cloning Is Essential Knowledge
Impersonation and Social Engineering Risks: Voice cloning enables highly believable impersonation. Attackers can mimic a trusted voice to trick people into sharing confidential data or performing critical actions. Understanding this helps in recognizing its misuse and building defenses accordingly. This is part of vishing (voice phishing). As an analyst, you need to recognize the signs of voice-based deepfakes. An unfamiliar context in a familiar voice? That’s a red flag.
Testing Voice-Based Security Systems: Many systems use voice recognition for authentication. Voice cloning helps security teams evaluate whether these systems can be bypassed or need enhancements. Using voice clones can expose weaknesses that wouldn’t be discovered through traditional testing methods.
Forensic Analysis of Audio Evidence: In digital investigations, distinguishing real voices from synthetic ones is crucial. Knowing how voice cloning works allows investigators to analyze audio evidence more accurately and determine if tampering has occurred.
Training and Awareness for Users: Employees are often the weakest link. Educating them about how voice cloning can be used in social engineering makes them more resilient. You can’t train others effectively unless you understand how voice cloning works and how real it can sound.
Legitimate use case innovations and Applications: Voice cloning is also valuable in non-security areas, like giving a voice to those who’ve lost theirs, enhancing storytelling in games or films, or recreating the voices of historical figures. Understanding the tech allows for ethical and innovative applications in these fields.
Privacy and Consent Considerations: Voice cloning raises serious consent and privacy issues, especially if it’s done without a person’s permission. If you understand or discover that unethical practices are occurring, you can report them or advocate for organizations to take appropriate action.
Understanding How Voice Cloning Works
Voice cloning is a technology that uses artificial intelligence (AI) to create a synthetic version of a person’s voice. This cloned voice can then be used to say anything, even if the person never actually spoke those words. The process works in three main stages: data collection, machine learning, and voice generation.
Stage 1: User Input
The process starts with the user either recording or uploading a sample of their voice. This sample doesn’t need to be very long — sometimes just a few minutes of clear speech is enough. The AI system uses this audio to learn how the person speaks, including details like accent, pitch, rhythm, and tone. This is similar to how a musician might listen carefully to mimic another musician’s style.
Stage 2: Machine Learning and Model Training
Once the voice sample is collected, it is sent into a machine learning pipeline. This pipeline has three key components:
First, a Feature Extractor breaks the audio into important linguistic elements. It analyzes how the words are pronounced, the pauses between them, the intonation, and other speech patterns. These patterns help the AI model understand the “style” of the voice.
Next, these linguistic patterns are passed into an Acoustic Model, which interprets how the speech should sound. It focuses on the acoustic features — the qualities that make the voice unique, like its timbre or texture.
Finally, a Vocoder takes those acoustic features and reconstructs them into an actual audio waveform. This is the stage where the computer creates a new audio file that mimics the original speaker’s voice but can say completely new content.
Stage 3: Cloned Voice Output
Once the AI model has been trained using the voice sample and passed through all three stages, it is ready to generate the cloned voice. At this point, a user can simply type in any text, and the system will speak it out loud using the synthetic version of the original voice. The final result sounds natural and convincingly close to the person’s real speech.

In a world where voices can be cloned with remarkable accuracy, how do we distinguish between authentic and synthesized speech?
Voice Watermarking
Voice watermarking is the process of embedding inaudible digital signals — kind of like an invisible fingerprint — into an audio file. These embedded signals don’t change how the audio sounds to the human ear but can be detected and verified by machines.
What Is Voice Watermarking?
Voice watermarking is a technique that embeds hidden identification signals into audio recordings. These digital markers remain inaudible to human ears but can be detected by specialized software.
Think of it as a secret signature that proves the authenticity of a recording or traces its origin. Unlike standard audio watermarks used primarily for copyright protection, voice watermarks specifically designed for anti-spoofing serve as an authentication mechanism against voice cloning attacks.
How Voice Watermarking works:
The process involves several sophisticated steps:
Signal Analysis: The original voice recording is analyzed in the frequency domain.
Watermark Encoding: A unique digital pattern is mathematically embedded into specific frequency bands where human hearing is less sensitive.
Robustness Testing: The watermark is designed to survive common audio processing like compression, trimming, or speed adjustments.
Verification Protocol: Special detection algorithms can later extract and verify the watermark, confirming authenticity. What makes this technology particularly valuable is its resilience — quality watermarks persist even after the audio undergoes compression, conversion, or other modifications.

Why is This Important?
With voice cloning tools becoming increasingly realistic, anyone’s voice can be copied with just a few samples. That poses serious risks — fraudulent calls, fake voice commands, deepfake audio in legal or political contexts.
Voice watermarking:
Helps prove the authenticity of an audio file.
Provides a chain of custody for audio in sensitive environments (like courtrooms, news media, or government).
Acts as a spoof detection mechanism to identify manipulated or AI-generated voices.
Example
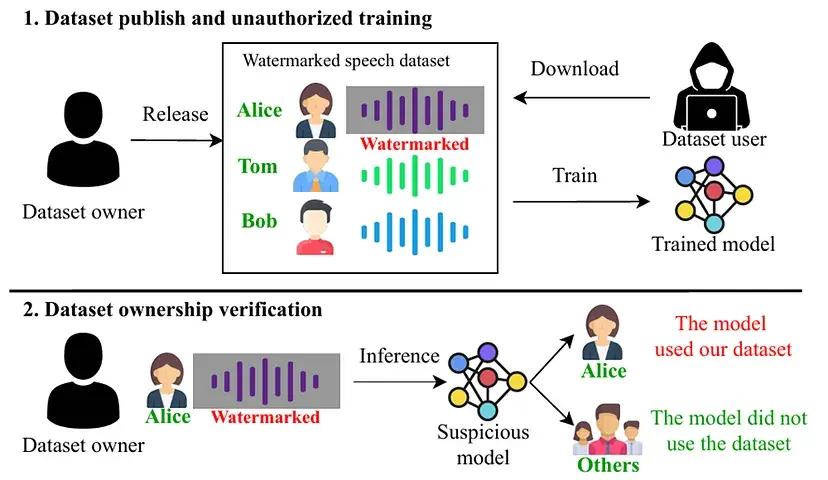
In the first part, a dataset owner releases a set of speech samples, which includes watermarked audio — hidden signals embedded in certain voices (like Alice’s). A malicious user downloads this dataset and trains an AI model without permission.
In the second part, the dataset owner later suspects the model was trained using their data. By testing (inference) the model with the watermarked voice sample, they can check whether the model recognizes Alice’s watermarked voice.
If it does, it’s proof that their dataset was used — even if the data was stolen or reused without credit. This process provides a powerful method to verify data misuse and enforce dataset ownership rights in AI systems.
Technical Challenges
Like all security tech, voice watermarking faces a balancing act:
Imperceptibility vs. Detectability
If the watermark is too strong, it might distort the audio. Too weak, and it becomes easy to remove or can’t be detected.
Algorithm Complexity
The embedding and detection algorithms must be smart enough to survive manipulations but also lightweight enough for real-time or near real-time use.
Device and Format Variability
A good watermark needs to survive changes in file format, sampling rate, or speaker hardware without breaking down.
How to protect yourself?

Limit Sharing Voice Recordings Online
Use Code Words for Verification
Be Wary of Urgent Voice Requests
Don’t Trust Caller ID Alone
Avoid Sharing Personal Info Over Voice Calls
Educate Your Inner Circle
Use Voice Biometric Authentication Cautiously
Regularly Monitor Financial and Communication Accounts
Report Suspicious Voice Activities
Stay secure! See you next Thursday!



Comments